Symmetric Multi-Processing
- Kernel Concurrency
- Atomic operations
- Spin locks
- Cache thrashing
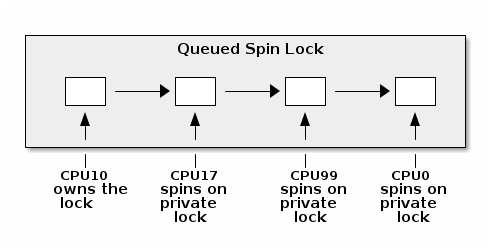
- Optimized spin locks
- Process and Interrupt Context Synchronization
- Mutexes
- Per CPU data
- Memory Ordering and Barriers
- Read-Copy Update
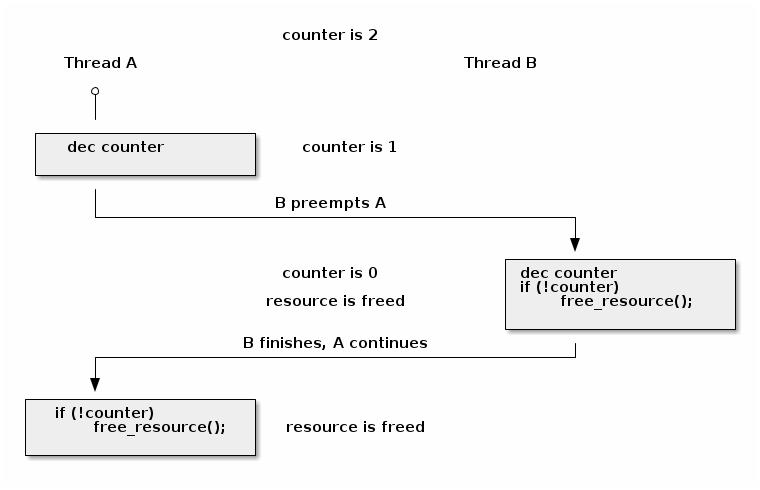
void release_resource()
{
counter--;
if (!counter)
free_resource();
}
atomic_inc(), atomic_dec(),
atomic_add(), atomic_sub()atomic_dec_and_test(), atomic_sub_and_test()test_bit(), set_bit(),
change_bit()test_and_set_bit(), test_and_clear_bit(),
test_and_change_bit()atomic_dec_and_test() to implement resource counter releasevoid release_resource()
{
if (atomic_dec_and_test(&counter))
free_resource();
}
#define local_irq_disable() \
asm volatile („cli” : : : „memory”)
#define local_irq_enable() \
asm volatile („sti” : : : „memory”)
#define local_irq_save(flags) \
asm volatile ("pushf ; pop %0" :"=g" (flags)
: /* no input */: "memory") \
asm volatile("cli": : :"memory")
#define local_irq_restore(flags) \
asm volatile ("push %0 ; popf"
: /* no output */
: "g" (flags) :"memory", "cc");
spin_lock:
lock bts [my_lock], 0
jc spin_lock
/* critical section */
spin_unlock:
mov [my_lock], 0
bts dts, src - bit test and set; it copies the src bit from the dts memory address to the carry flag and then sets it:
CF <- dts[src]
dts[src] <- 1
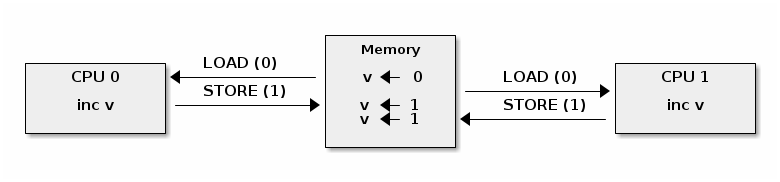
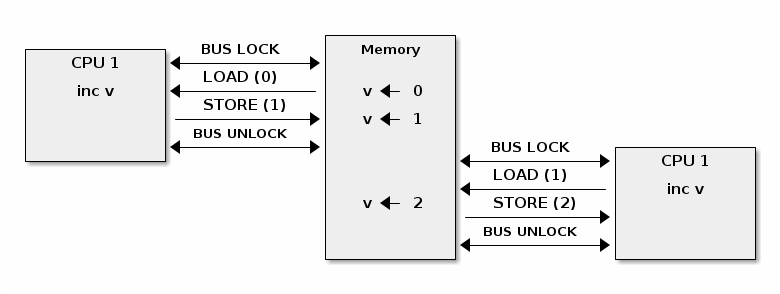
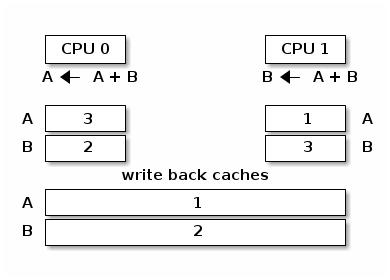
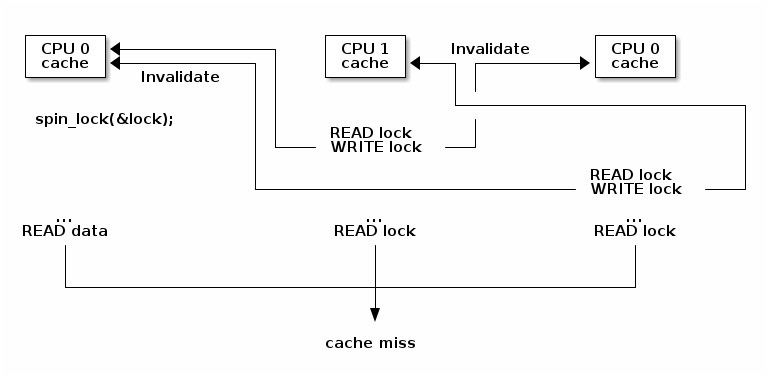
Cache thrashing occurs when multiple cores are trying to read and write to the same memory resulting in excessive cache misses.
Since spin locks continuously access memory during lock contention, cache thrashing is a common occurrence due to the way cache coherency is implemented.
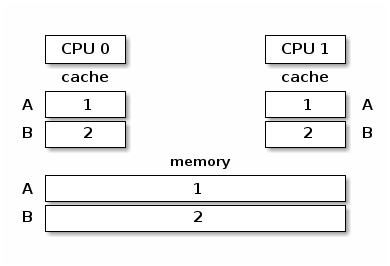
Bus snooping is simpler but it performs poorly when the number of cores goes beyond 32-64.
Directory based cache coherence protocols scale much better (up to thousands of cores) and are usually used in NUMA systems.
spin_lock:
rep ; nop
test lock_addr, 1
jnz spin_lock
lock bts lock_addr
jc spin_lock
spin_lock_irqsave() and
spin_lock_restore() combine the two operations)spin_lock_bh() (which combines
local_bh_disable() and spin_lock()) and
spin_unlock_bh() (which combines spin_unlock() and
local_bh_enable())spin_lock() and
spin_unlock() (or spin_lock_irqsave() and
spin_lock_irqrestore() if sharing data with interrupt
handlers)
Preemption is configurable: when active it provides better latency and response time, while when deactivated it provides better throughput.
Preemption is disabled by spin locks and mutexes but it can be manually disabled as well (by core kernel code).
#define PREEMPT_BITS 8
#define SOFTIRQ_BITS 8
#define HARDIRQ_BITS 4
#define NMI_BITS 1
#define preempt_disable() preempt_count_inc()
#define local_bh_disable() add_preempt_count(SOFTIRQ_OFFSET)
#define local_bh_enable() sub_preempt_count(SOFTIRQ_OFFSET)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK))
#define in_interrupt() irq_count()
asmlinkage void do_softirq(void)
{
if (in_interrupt()) return;
...
mutex_lock() fast pathvoid __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}
static __always_inline bool __mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
if (!atomic_long_cmpxchg_acquire(&lock->owner, 0UL, curr))
return true;
return false;
}
mutex_lock() slow path...
spin_lock(&lock->wait_lock);
...
/* add waiting tasks to the end of the waitqueue (FIFO): */
list_add_tail(&waiter.list, &lock->wait_list);
...
waiter.task = current;
...
for (;;) {
if (__mutex_trylock(lock))
goto acquired;
...
spin_unlock(&lock->wait_lock);
...
set_current_state(state);
spin_lock(&lock->wait_lock);
}
spin_lock(&lock->wait_lock);
acquired:
__set_current_state(TASK_RUNNING);
mutex_remove_waiter(lock, &waiter, current);
spin_lock(&lock->wait_lock);
...
mutex_unlock() fast pathvoid __sched mutex_unlock(struct mutex *lock)
{
if (__mutex_unlock_fast(lock))
return;
__mutex_unlock_slowpath(lock, _RET_IP_);
}
static __always_inline bool __mutex_unlock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
if (atomic_long_cmpxchg_release(&lock->owner, curr, 0UL) == curr)
return true;
return false;
}
void __mutex_lock_slowpath(struct mutex *lock)
{
...
if (__mutex_waiter_is_first(lock, &waiter))
__mutex_set_flag(lock, MUTEX_FLAG_WAITERS);
...
mutex_unlock() slow path...
spin_lock(&lock->wait_lock);
if (!list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter;
waiter = list_first_entry(&lock->wait_list, struct mutex_waiter,
list);
next = waiter->task;
wake_q_add(&wake_q, next);
}
...
spin_unlock(&lock->wait_lock);
...
wake_up_q(&wake_q);
| C code | Compiler generated code |
a = 1;
b = 2;
|
MOV R10, 1
MOV R11, 2
STORE R11, b
STORE R10, a
|
rmb(), smp_rmb()) is used to
make sure that no read operation crosses the barrier; that is,
all read operation before the barrier are complete before
executing the first instruction after the barrierwmb(), smp_wmb()) is used to
make sure that no write operation crosses the barriermb(), smp_mb()) is used
to make sure that no write or read operation crosses the barrier
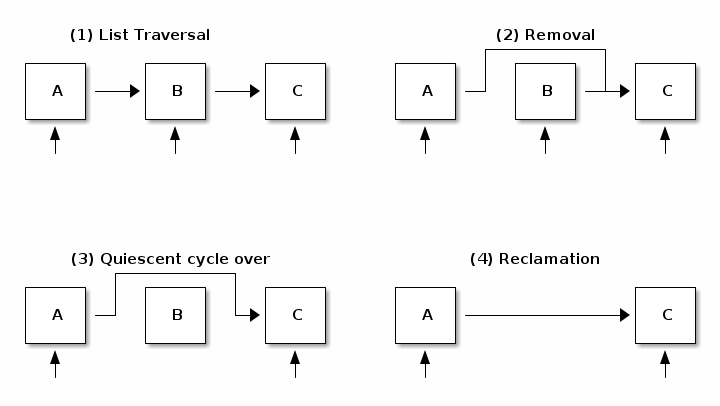
/* list traversal */
rcu_read_lock();
list_for_each_entry_rcu(i, head) {
/* no sleeping, blocking calls or context switch allowed */
}
rcu_read_unlock();
/* list element delete */
spin_lock(&lock);
list_del_rcu(&node->list);
spin_unlock(&lock);
synchronize_rcu();
kfree(node);
/* list element add */
spin_lock(&lock);
list_add_rcu(head, &node->list);
spin_unlock(&lock);