Symmetric Multi-Processing
- Kernel Concurrency
- Atomic operations
- Spin locks
- Cache thrashing
- Optimized spin locks
- Process and Interrupt Context Synchronization
- Mutexes
- Per CPU data
- Memory Ordering and Barriers
- Read-Copy Update
Race conditions
- there are at least two execution contexts that run in "parallel":
- truly run in parallel (e.g. two system calls running on different processors)
- one of the contexts can arbitrary preempt the other (e.g. an interrupt preempts a system call)
- the execution contexts perform read-write accesses to shared memory
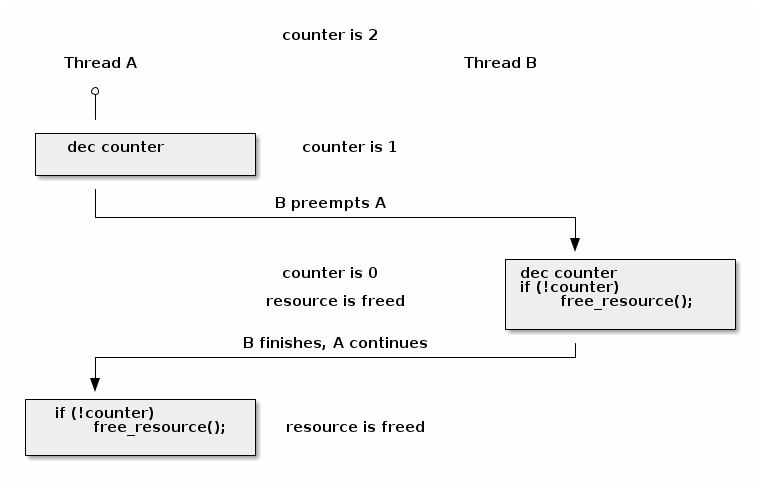
Race condition: resource counter release
void release_resource()
{
counter--;
if (!counter)
free_resource();
}
Race condition scenario
Avoiding race conditions
- make the critical section atomic (e.g. use atomic instructions)
- disable preemption during the critical section (e.g. disable interrupts, bottom-half handlers, or thread preemption)
- serialize the access to the critical section (e.g. use spin locks or mutexes to allow only one context or thread in the critical section)
Linux kernel concurrency sources
- single core systems, non-preemptive kernel: the current process can be preempted by interrupts
- single core systems, preemptive kernel: above + the current process can be preempted by other processes
- multi-core systems: above + the current process can run in parallel with another process or with an interrupt running on another processor
Atomic operations
- integer based:
- simple:
atomic_inc(),atomic_dec(),atomic_add(),atomic_sub() - conditional:
atomic_dec_and_test(),atomic_sub_and_test()
- simple:
- bit based:
- simple:
test_bit(),set_bit(),change_bit() - conditional:
test_and_set_bit(),test_and_clear_bit(),test_and_change_bit()
- simple:
Using atomic_dec_and_test() to implement resource counter release
void release_resource()
{
if (atomic_dec_and_test(&counter))
free_resource();
}
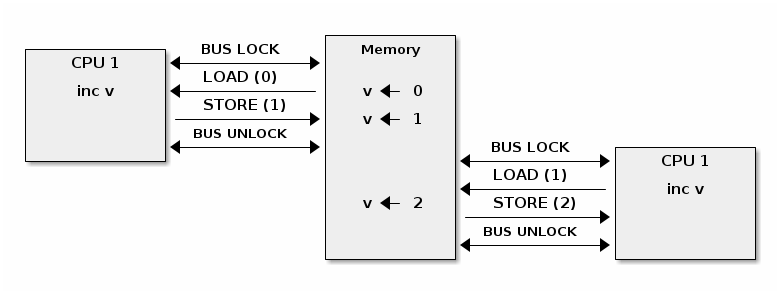
Atomic operations may not be atomic on SMP systems
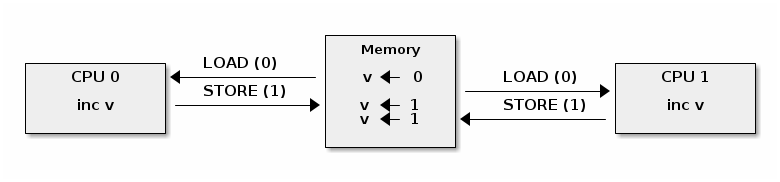
Fixing atomic operations for SMP systems (x86)
Synchronization with interrupts (x86)
#define local_irq_disable() \
asm volatile („cli” : : : „memory”)
#define local_irq_enable() \
asm volatile („sti” : : : „memory”)
#define local_irq_save(flags) \
asm volatile ("pushf ; pop %0" :"=g" (flags)
: /* no input */: "memory") \
asm volatile("cli": : :"memory")
#define local_irq_restore(flags) \
asm volatile ("push %0 ; popf"
: /* no output */
: "g" (flags) :"memory", "cc");
Spin Lock Implementation Example (x86)
spin_lock:
lock bts [my_lock], 0
jc spin_lock
/* critical section */
spin_unlock:
mov [my_lock], 0
bts dts, src - bit test and set; it copies the src bit from the dts memory address to the carry flag and then sets it:
CF <- dts[src]
dts[src] <- 1
Lock Contention
- There is lock contention when at least one core spins trying to enter the critical section lock
- Lock contention grows with the critical section size, time spent in the critical section and the number of cores in the system
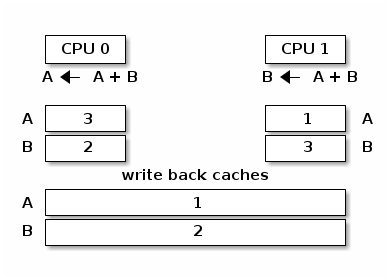
Cache Thrashing
Cache thrashing occurs when multiple cores are trying to read and write to the same memory resulting in excessive cache misses.
Since spin locks continuously access memory during lock contention, cache thrashing is a common occurrence due to the way cache coherency is implemented.
Synchronized caches and memory
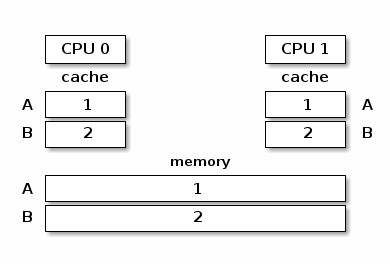
Unsynchronized caches and memory
Cache Coherency Protocols
- Bus snooping (sniffing) based: memory bus transactions are monitored by caches and they take actions to preserve coherency
- Directory based: there is a separate entity (directory) that maintains the state of caches; caches interact with directory to preserve coherency
Bus snooping is simpler but it performs poorly when the number of cores goes beyond 32-64.
Directory based cache coherence protocols scale much better (up to thousands of cores) and are usually used in NUMA systems.
MESI Cache Coherence Protocol
- Caching policy: write back
- Cache line states
- Modified: owned by a single core and dirty
- Exclusive: owned by a single core and clean
- Shared: shared between multiple cores and clean
- Invalid : the line is not cached
MESI State Transitions
- Invalid -> Exclusive: read request, all other cores have the line in Invalid; line loaded from memory
- Invalid -> Shared: read request, at least one core has the line in Shared or Exclusive; line loaded from sibling cache
- Invalid/Shared/Exclusive -> Modified: write request; all other cores invalidate the line
- Modified -> Invalid: write request from other core; line is flushed to memory
Cache thrashing due to spin lock contention
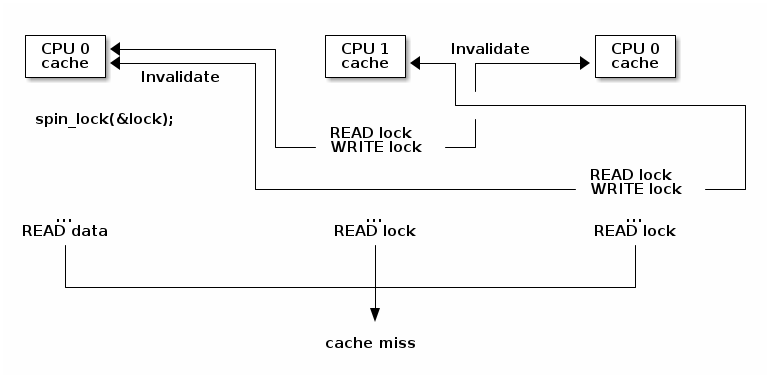
Optimized spin lock (KeAcquireSpinLock)
spin_lock:
rep ; nop
test lock_addr, 1
jnz spin_lock
lock bts lock_addr
jc spin_lock
- we first test the lock read only, using a non atomic instructions, to avoid writes and thus invalidate operations while we spin
- only when the lock might be free, we try to acquire it
Queued Spin Locks
Process and Interrupt Handler Synchronization Deadlock
- In the process context we take the spin lock
- An interrupt occurs and it is scheduled on the same CPU core
- The interrupt handler runs and tries to take the spin lock
- The current CPU will deadlock
Interrupt Synchronization for SMP
- In process context: disable interrupts and acquire a spin lock;
this will protect both against interrupt or other CPU cores race
conditions (
spin_lock_irqsave()andspin_lock_restore()combine the two operations) - In interrupt context: take a spin lock; this will will protect against race conditions with other interrupt handlers or process context running on different processors
Bottom-Half Synchronization for SMP
- In process context use
spin_lock_bh()(which combineslocal_bh_disable()andspin_lock()) andspin_unlock_bh()(which combinesspin_unlock()andlocal_bh_enable()) - In bottom half context use:
spin_lock()andspin_unlock()(orspin_lock_irqsave()andspin_lock_irqrestore()if sharing data with interrupt handlers)
Preemption
Preemption is configurable: when active it provides better latency and response time, while when deactivated it provides better throughput.
Preemption is disabled by spin locks and mutexes but it can be manually disabled as well (by core kernel code).
Preemption and Bottom-Half Masking
#define PREEMPT_BITS 8
#define SOFTIRQ_BITS 8
#define HARDIRQ_BITS 4
#define NMI_BITS 1
#define preempt_disable() preempt_count_inc()
#define local_bh_disable() add_preempt_count(SOFTIRQ_OFFSET)
#define local_bh_enable() sub_preempt_count(SOFTIRQ_OFFSET)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK))
#define in_interrupt() irq_count()
asmlinkage void do_softirq(void)
{
if (in_interrupt()) return;
...
Mutexes
- They don't "waste" CPU cycles; system throughput is better than spin locks if context switch overhead is lower than medium spinning time
- They can't be used in interrupt context
- They have a higher latency than spin locks
mutex_lock() fast path
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}
static __always_inline bool __mutex_trylock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
if (!atomic_long_cmpxchg_acquire(&lock->owner, 0UL, curr))
return true;
return false;
}
mutex_lock() slow path
...
spin_lock(&lock->wait_lock);
...
/* add waiting tasks to the end of the waitqueue (FIFO): */
list_add_tail(&waiter.list, &lock->wait_list);
...
waiter.task = current;
...
for (;;) {
if (__mutex_trylock(lock))
goto acquired;
...
spin_unlock(&lock->wait_lock);
...
set_current_state(state);
spin_lock(&lock->wait_lock);
}
spin_lock(&lock->wait_lock);
acquired:
__set_current_state(TASK_RUNNING);
mutex_remove_waiter(lock, &waiter, current);
spin_lock(&lock->wait_lock);
...
mutex_unlock() fast path
void __sched mutex_unlock(struct mutex *lock)
{
if (__mutex_unlock_fast(lock))
return;
__mutex_unlock_slowpath(lock, _RET_IP_);
}
static __always_inline bool __mutex_unlock_fast(struct mutex *lock)
{
unsigned long curr = (unsigned long)current;
if (atomic_long_cmpxchg_release(&lock->owner, curr, 0UL) == curr)
return true;
return false;
}
void __mutex_lock_slowpath(struct mutex *lock)
{
...
if (__mutex_waiter_is_first(lock, &waiter))
__mutex_set_flag(lock, MUTEX_FLAG_WAITERS);
...
mutex_unlock() slow path
...
spin_lock(&lock->wait_lock);
if (!list_empty(&lock->wait_list)) {
/* get the first entry from the wait-list: */
struct mutex_waiter *waiter;
waiter = list_first_entry(&lock->wait_list, struct mutex_waiter,
list);
next = waiter->task;
wake_q_add(&wake_q, next);
}
...
spin_unlock(&lock->wait_lock);
...
wake_up_q(&wake_q);
Per CPU data
- No need to synchronize to access the data
- No contention, no performance impact
- Well suited for distributed processing where aggregation is only seldom necessary (e.g. statistics counters)
Out of Order Compiler Generated Code
| C code | Compiler generated code |
a = 1;
b = 2;
|
MOV R10, 1
MOV R11, 2
STORE R11, b
STORE R10, a
|
Barriers
- A read barrier (
rmb(),smp_rmb()) is used to make sure that no read operation crosses the barrier; that is, all read operation before the barrier are complete before executing the first instruction after the barrier - A write barrier (
wmb(),smp_wmb()) is used to make sure that no write operation crosses the barrier - A simple barrier (
mb(),smp_mb()) is used to make sure that no write or read operation crosses the barrier
Read Copy Update (RCU)
- Read-only lock-less access at the same time with write access
- Write accesses still requires locks in order to avoid races between writers
- Requires unidirectional traversal by readers
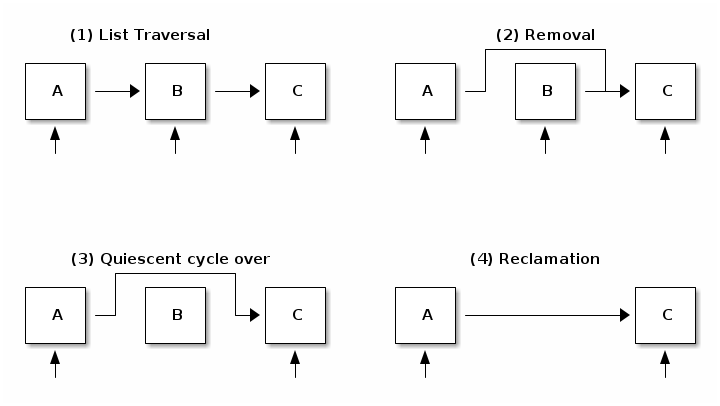
Removal and Reclamation
- Removal: removes references to elements. Some old readers may still see the old reference so we can't free the element.
- Elimination: free the element. This action is postponed until all existing readers finish traversal (quiescent cycle). New readers won't affect the quiescent cycle.
RCU List Delete
RCU list APIs cheat sheet
/* list traversal */
rcu_read_lock();
list_for_each_entry_rcu(i, head) {
/* no sleeping, blocking calls or context switch allowed */
}
rcu_read_unlock();
/* list element delete */
spin_lock(&lock);
list_del_rcu(&node->list);
spin_unlock(&lock);
synchronize_rcu();
kfree(node);
/* list element add */
spin_lock(&lock);
list_add_rcu(head, &node->list);
spin_unlock(&lock);