SO2 Lab 10 - Networking¶
Lab objectives¶
- Understanding the Linux kernel networking architecture
- Acquiring practical IP packet management skills using a packet filter or firewall
- Familiarize yourself with how to use sockets at the Linux kernel level
Overview¶
The development of the Internet has led to an exponential increase in network applications and, as a consequence, to increasing the speed and productivity requirements of an operating system's networking subsystem. The networking subsystem is not an essential component of an operating system kernel (the Linux kernel can be compiled without networking support). It is, however, quite unlikely for a computing system (or even an embedded device) to have a non-networked operating system due to the need for connectivity. Modern operating systems use the TCP/IP stack. Their kernel implements protocols up to the transport layer, while application layer protocols are typically implemented in user space (HTTP, FTP, SSH, etc.).
Networking in user space¶
In user space the abstraction of network communication is the socket. The
socket abstracts a communication channel and is the kernel-based TCP/IP stack
interaction interface. An IP socket is associated with an IP address, the
transport layer protocol used (TCP, UDP etc) and a port. Common function calls
that use sockets are: creation (socket), initialization
(bind), connecting (connect), waiting for a connection
(listen, accept), closing a socket (close).
Network communication is accomplished via read/write or recv/send calls
for TCP sockets and recvfrom/sendto for UDP sockets. Transmission and
reception operations are transparent to the application, leaving encapsulation
and transmission over network at the kernel's discretion. However, it is
possible to implement the TCP/IP stack in user space using raw sockets (the
PF_PACKET option when creating a socket), or implementing an application
layer protocol in kernel (TUX web server).
For more details about user space programming using sockets, see Beej's Guide to Network Programming Using Internet Sockets.
Linux networking¶
The Linux kernel provides three basic structures for working with network
packets: struct socket, struct sock and struct
sk_buff.
The first two are abstractions of a socket:
struct socketis an abstraction very close to user space, ie BSD sockets used to program network applications;struct sockor INET socket in Linux terminology is the network representation of a socket.
The two structures are related: the struct socket contains an INET
socket field, and the struct sock has a BSD socket that holds it.
The struct sk_buff structure is the representation of a network packet
and its status. The structure is created when a kernel packet is received,
either from the user space or from the network interface.
The struct socket structure¶
The struct socket structure is the kernel representation of a BSD
socket, the operations that can be executed on it are similar to those offered
by the kernel (through system calls). Common operations with sockets
(creation, initialization/bind, closing, etc.) result in specific system
calls; they work with the struct socket structure.
The struct socket operations are described in net/socket.c and
are independent of the protocol type. The struct socket structure is thus
a generic interface over particular network operations implementations.
Typically, the names of these operations begin with the sock_ prefix.
Operations on the socket structure¶
Socket operations are:
Creation¶
Creation is similar to calling the socket() function in user space, but the
struct socket created will be stored in the res parameter:
int sock_create(int family, int type, int protocol, struct socket **res)creates a socket after thesocket()system call;int sock_create_kern(struct net *net, int family, int type, int protocol, struct socket **res)creates a kernel socket;int sock_create_lite(int family, int type, int protocol, struct socket **res)creates a kernel socket without parameter sanity checks.
The parameters of these calls are as follows:
net, where it is present, used as reference to the network namespace used; we will usually initialize it withinit_net;familyrepresents the family of protocols used in the transfer of information; they usually begin with thePF_(Protocol Family) string; the constants representing the family of protocols used are found inlinux/socket.h, of which the most commonly used isPF_INET, for TCP/IP protocols;typeis the type of socket; the constants used for this parameter are found inlinux/net.h, of which the most used areSOCK_STREAMfor a connection based source-to-destination communication andSOCK_DGRAMfor connectionless communication;protocolrepresents the protocol used and is closely related to thetypeparameter; the constants used for this parameter are found inlinux/in.h, of which the most used areIPPROTO_TCPfor TCP andIPPROTO_UDPfor UDP.
To create a TCP socket in kernel space, you must call:
struct socket *sock;
int err;
err = sock_create_kern(&init_net, PF_INET, SOCK_STREAM, IPPROTO_TCP, &sock);
if (err < 0) {
/* handle error */
}
and for creating UDP sockets:
struct socket *sock;
int err;
err = sock_create_kern(&init_net, PF_INET, SOCK_DGRAM, IPPROTO_UDP, &sock);
if (err < 0) {
/* handle error */
}
A usage sample is part of the sys_socket() system call handler:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
/* Check the SOCK_* constants for consistency. */
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
flags = type & ~SOCK_TYPE_MASK;
if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return -EINVAL;
type &= SOCK_TYPE_MASK;
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
goto out;
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
Closing¶
Close connection (for sockets using connection) and release associated resources:
void sock_release(struct socket *sock)calls thereleasefunction in theopsfield of the socket structure:
void sock_release(struct socket *sock)
{
if (sock->ops) {
struct module *owner = sock->ops->owner;
sock->ops->release(sock);
sock->ops = NULL;
module_put(owner);
}
//...
}
Sending/receiving messages¶
The messages are sent/received using the following functions:
int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags);int kernel_recvmsg(struct socket *sock, struct msghdr *msg, struct kvec *vec, size_t num, size_t size, int flags);int sock_sendmsg(struct socket *sock, struct msghdr *msg);int kernel_sendmsg(struct socket *sock, struct msghdr *msg, struct kvec *vec, size_t num, size_t size);
The message sending/receiving functions will then call the sendmsg/
recvmsg function in the ops field of the socket. Functions
containing kernel_ as a prefix are used when the socket is used in the
kernel.
The parameters are:
msg, astruct msghdrstructure, containing the message to be sent/received. Among the important components of this structure aremsg_nameandmsg_namelen, which, for UDP sockets, must be filled in with the address to which the message is sent (struct sockaddr_in);vec, astruct kvecstructure, containing a pointer to the buffer containing its data and size; as can be seen, it has a similar structure to thestruct iovecstructure (thestruct iovecstructure corresponds to the user space data, and thestruct kvecstructure corresponds to kernel space data).
A usage example can be seen in the sys_sendto() system call handler:
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len,
unsigned int, flags, struct sockaddr __user *, addr,
int, addr_len)
{
struct socket *sock;
struct sockaddr_storage address;
int err;
struct msghdr msg;
struct iovec iov;
int fput_needed;
err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
msg.msg_name = NULL;
msg.msg_control = NULL;
msg.msg_controllen = 0;
msg.msg_namelen = 0;
if (addr) {
err = move_addr_to_kernel(addr, addr_len, &address);
if (err < 0)
goto out_put;
msg.msg_name = (struct sockaddr *)&address;
msg.msg_namelen = addr_len;
}
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
msg.msg_flags = flags;
err = sock_sendmsg(sock, &msg);
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
}
The struct socket fields¶
/**
* struct socket - general BSD socket
* @state: socket state (%SS_CONNECTED, etc)
* @type: socket type (%SOCK_STREAM, etc)
* @flags: socket flags (%SOCK_NOSPACE, etc)
* @ops: protocol specific socket operations
* @file: File back pointer for gc
* @sk: internal networking protocol agnostic socket representation
* @wq: wait queue for several uses
*/
struct socket {
socket_state state;
short type;
unsigned long flags;
struct socket_wq __rcu *wq;
struct file *file;
struct sock *sk;
const struct proto_ops *ops;
};
The noteworthy fields are:
ops- the structure that stores pointers to protocol-specific functions;sk- TheINET socketassociated with it.
The struct proto_ops structure¶
The struct proto_ops structure contains the implementations of the specific
operations implemented (TCP, UDP, etc.); these functions will be called from
generic functions through struct socket (sock_release(),
sock_sendmsg(), etc.)
The struct proto_ops structure therefore contains a number of function
pointers for specific protocol implementations:
struct proto_ops {
int family;
struct module *owner;
int (*release) (struct socket *sock);
int (*bind) (struct socket *sock,
struct sockaddr *myaddr,
int sockaddr_len);
int (*connect) (struct socket *sock,
struct sockaddr *vaddr,
int sockaddr_len, int flags);
int (*socketpair)(struct socket *sock1,
struct socket *sock2);
int (*accept) (struct socket *sock,
struct socket *newsock, int flags, bool kern);
int (*getname) (struct socket *sock,
struct sockaddr *addr,
int peer);
//...
}
The initialization of the ops field from struct socket is done in
the __sock_create() function, by calling the create() function,
specific to each protocol; an equivalent call is the implementation of the
__sock_create() function:
//...
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
//...
This will instantiate the function pointers with calls specific to the protocol
type associated with the socket. The sock_register() and
sock_unregister() calls are used to fill the net_families vector.
For the rest of the socket operations (other than creating, closing, and
sending/receiving a message as described above in the Operations on the socket
structure section), the functions sent via pointers in this structure will be
called. For example, for bind, which associates a socket with a socket on
the local machine, we will have the following code sequence:
#define MY_PORT 60000
struct sockaddr_in addr = {
.sin_family = AF_INET,
.sin_port = htons (MY_PORT),
.sin_addr = { htonl (INADDR_LOOPBACK) }
};
//...
err = sock->ops->bind (sock, (struct sockaddr *) &addr, sizeof(addr));
if (err < 0) {
/* handle error */
}
//...
As you can see, for transmitting the address and port information that
will be associated with the socket, a struct sockaddr_in is filled.
The struct sock structure¶
The struct sock describes an INET socket. Such a structure is
associated with a user space socket and implicitly with a struct
socket structure. The structure is used to store information about the status
of a connection. The structure's fields and associated operations usually begin
with the sk_ string. Some fields are listed below:
struct sock {
//...
unsigned int sk_padding : 1,
sk_no_check_tx : 1,
sk_no_check_rx : 1,
sk_userlocks : 4,
sk_protocol : 8,
sk_type : 16;
//...
struct socket *sk_socket;
//...
struct sk_buff *sk_send_head;
//...
void (*sk_state_change)(struct sock *sk);
void (*sk_data_ready)(struct sock *sk);
void (*sk_write_space)(struct sock *sk);
void (*sk_error_report)(struct sock *sk);
int (*sk_backlog_rcv)(struct sock *sk,
struct sk_buff *skb);
void (*sk_destruct)(struct sock *sk);
};
sk_protocolis the type of protocol used by the socket;sk_typeis the socket type (SOCK_STREAM,SOCK_DGRAM, etc.);sk_socketis the BSD socket that holds it;sk_send_headis the list ofstruct sk_buffstructures for transmission;- the function pointers at the end are callbacks for different situations.
Initializing the struct sock and attaching it to a BSD socket is done
using the callback created from net_families (called
__sock_create()). Here's how to initialize the struct sock
structure for the IP protocol, in the inet_create() function:
/*
* Create an inet socket.
*/
static int inet_create(struct net *net, struct socket *sock, int protocol,
int kern)
{
struct sock *sk;
//...
err = -ENOBUFS;
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
if (!sk)
goto out;
err = 0;
if (INET_PROTOSW_REUSE & answer_flags)
sk->sk_reuse = SK_CAN_REUSE;
//...
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
//...
}
The struct sk_buff structure¶
The struct sk_buff (socket buffer) describes a network packet. The
structure fields contain information about both the header and packet contents,
the protocols used, the network device used, and pointers to the other
struct sk_buff. A summary description of the content of the structure
is presented below:
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
union {
struct net_device *dev;
/* Some protocols might use this space to store information,
* while device pointer would be NULL.
* UDP receive path is one user.
*/
unsigned long dev_scratch;
};
};
struct rb_node rbnode; /* used in netem & tcp stack */
};
struct sock *sk;
union {
ktime_t tstamp;
u64 skb_mstamp;
};
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8);
unsigned long _skb_refdst;
void (*destructor)(struct sk_buff *skb);
union {
struct {
unsigned long _skb_refdst;
void (*destructor)(struct sk_buff *skb);
};
struct list_head tcp_tsorted_anchor;
};
/* ... */
unsigned int len,
data_len;
__u16 mac_len,
hdr_len;
/* ... */
__be16 protocol;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
/* private: */
__u32 headers_end[0];
/* public: */
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize;
refcount_t users;
};
where:
nextandprevare pointers to the next, and previous element in the buffer list;devis the device which sends or receives the buffer;skis the socket associated with the buffer;destructoris the callback that deallocates the buffer;transport_header,network_header, andmac_headerare offsets between the beginning of the packet and the beginning of the various headers in the packets. They are internally maintained by the various processing layers through which the packet passes. To get pointers to the headers, use one of the following functions:tcp_hdr(),udp_hdr(),ip_hdr(), etc. In principle, each protocol provides a function to get a reference to the header of that protocol within a received packet. Keep in mind that thenetwork_headerfield is not set until the packet reaches the network layer and thetransport_headerfield is not set until the packet reaches the transport layer.
The structure of an IP header
(struct iphdr) has the following fields:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__be16 tot_len;
__be16 id;
__be16 frag_off;
__u8 ttl;
__u8 protocol;
__sum16 check;
__be32 saddr;
__be32 daddr;
/*The options start here. */
};
where:
protocolis the transport layer protocol used;saddris the source IP address;daddris the destination IP address.
The structure of a TCP header
(struct tcphdr) has the following fields:
struct tcphdr {
__be16 source;
__be16 dest;
__be32 seq;
__be32 ack_seq;
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4,
doff:4,
fin:1,
syn:1,
rst:1,
psh:1,
ack:1,
urg:1,
ece:1,
cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window;
__sum16 check;
__be16 urg_ptr;
};
where:
sourceis the source port;destis the destination port;syn,ack,finare the TCP flags used; for a more detailed view, see this diagram.
The structure of a UDP header
(struct udphdr) has the following fields:
struct udphdr {
__be16 source;
__be16 dest;
__be16 len;
__sum16 check;
};
where:
sourceis the source port;destis the destination port.
An example of accessing the information present in the headers of a network packet is as follows:
struct sk_buff *skb;
struct iphdr *iph = ip_hdr(skb); /* IP header */
/* iph->saddr - source IP address */
/* iph->daddr - destination IP address */
if (iph->protocol == IPPROTO_TCP) { /* TCP protocol */
struct tcphdr *tcph = tcp_hdr(skb); /* TCP header */
/* tcph->source - source TCP port */
/* tcph->dest - destination TCP port */
} else if (iph->protocol == IPPROTO_UDP) { /* UDP protocol */
struct udphdr *udph = udp_hdr(skb); /* UDP header */
/* udph->source - source UDP port */
/* udph->dest - destination UDP port */
}
Conversions¶
In different systems, there are several ways of ordering bytes in a word (Endianness), including: Big Endian (the most significant byte first) and Little Endian (the least significant byte first). Since a network interconnects systems with different platforms, the Internet has imposed a standard sequence for the storage of numerical data, called network byte-order. In contrast, the byte sequence for the representation of numerical data on the host computer is called host byte-order. Data received/sent from/to the network is in the network byte-order format and should be converted between this format and the host byte-order.
For converting we use the following macros:
u16 htons(u16 x)converts a 16 bit integer from host byte-order to network byte-order (host to network short);u32 htonl(u32 x)converts a 32 bit integer from host byte-order to network byte-order (host to network long);u16 ntohs(u16 x)converts a 16 bit integer from network byte-order to host byte-order (network to host short);u32 ntohl(u32 x)converts a 32 bit integer from network byte-order to host byte-order (network to host long).
netfilter¶
Netfilter is the name of the kernel interface for capturing network packets for modifying/analyzing them (for filtering, NAT, etc.). The netfilter interface is used in user space by iptables.
In the Linux kernel, packet capture using netfilter is done by attaching hooks. Hooks can be specified in different locations in the path followed by a kernel network packet, as needed. An organization chart with the route followed by a package and the possible areas for a hook can be found here.
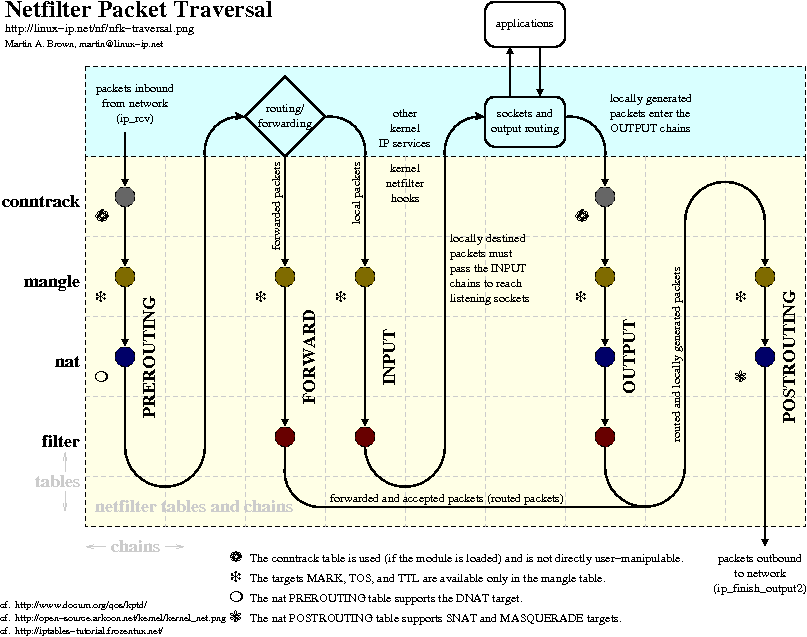{kind=link}
The header included when using netfilter is linux/netfilter.h.
A hook is defined through the struct nf_hook_ops structure:
struct nf_hook_ops {
/* User fills in from here down. */
nf_hookfn *hook;
struct net_device *dev;
void *priv;
u_int8_t pf;
unsigned int hooknum;
/* Hooks are ordered in ascending priority. */
int priority;
};
where:
pfis the package type (PF_INET, etc.);
priorityis the priority; priorities are defined inuapi/linux/netfilter_ipv4.has follows:
enum nf_ip_hook_priorities {
NF_IP_PRI_FIRST = INT_MIN,
NF_IP_PRI_CONNTRACK_DEFRAG = -400,
NF_IP_PRI_RAW = -300,
NF_IP_PRI_SELINUX_FIRST = -225,
NF_IP_PRI_CONNTRACK = -200,
NF_IP_PRI_MANGLE = -150,
NF_IP_PRI_NAT_DST = -100,
NF_IP_PRI_FILTER = 0,
NF_IP_PRI_SECURITY = 50,
NF_IP_PRI_NAT_SRC = 100,
NF_IP_PRI_SELINUX_LAST = 225,
NF_IP_PRI_CONNTRACK_HELPER = 300,
NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX,
NF_IP_PRI_LAST = INT_MAX,
};
devis the device (network interface) on which the capture is intended;hooknumis the type of hook used. When a packet is captured, the processing mode is defined by thehooknumandhookfields. For IP, hook types are defined inlinux/netfilter.h:
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};
hookis the handler called when capturing a network packet (packet sent as astruct sk_buffstructure). Theprivatefield is private information handed to the handler. The capture handler prototype is defined by thenf_hookfntype:
struct nf_hook_state {
unsigned int hook;
u_int8_t pf;
struct net_device *in;
struct net_device *out;
struct sock *sk;
struct net *net;
int (*okfn)(struct net *, struct sock *, struct sk_buff *);
};
typedef unsigned int nf_hookfn(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state);
For the nf_hookfn() capture function, the priv parameter is the
private information with which the struct nf_hook_ops was
initialized. skb is the pointer to the captured network packet. Based on
skb information, packet filtering decisions are made. The function's
state parameter is the status information related to the packet capture,
including the input interface, the output interface, the priority, the hook
number. Priority and hook number are useful for allowing the same function to
be called by several hooks.
A capture handler can return one of the constants NF_*:
/* Responses from hook functions. */
#define NF_DROP 0
#define NF_ACCEPT 1
#define NF_STOLEN 2
#define NF_QUEUE 3
#define NF_REPEAT 4
#define NF_STOP 5
#define NF_MAX_VERDICT NF_STOP
NF_DROP is used to filter (ignore) a packet, and NF_ACCEPT is used to
accept a packet and forward it.
Registering/unregistering a hook is done using the functions defined in
linux/netfilter.h:
/* Function to register/unregister hook points. */
int nf_register_net_hook(struct net *net, const struct nf_hook_ops *ops);
void nf_unregister_net_hook(struct net *net, const struct nf_hook_ops *ops);
int nf_register_net_hooks(struct net *net, const struct nf_hook_ops *reg,
unsigned int n);
void nf_unregister_net_hooks(struct net *net, const struct nf_hook_ops *reg,
unsigned int n);
Attention
Prior to version 3.11-rc2 of the Linux kernel,
there are some restrictions related to the use of header extraction functions
from a struct sk_buff structure set as a parameter in a netfilter
hook. While the IP header can be obtained each time using ip_hdr(),
the TCP and UDP headers can be obtained with tcp_hdr() and
udp_hdr() only for packages that come from inside the system rather
than the ones that are received from outside the system. In the latter case,
you must manually calculate the header offset in the package:
// For TCP packets (iph->protocol == IPPROTO_TCP)
tcph = (struct tcphdr*)((__u32*)iph + iph->ihl);
// For UDP packets (iph->protocol == IPPROTO_UDP)
udph = (struct udphdr*)((__u32*)iph + iph->ihl);
This code works in all filtering situations, so it's recommended to use it instead of header access functions.
A usage example for a netfilter hook is shown below:
#include <linux/netfilter.h>
#include <linux/netfilter_ipv4.h>
#include <linux/net.h>
#include <linux/in.h>
#include <linux/skbuff.h>
#include <linux/ip.h>
#include <linux/tcp.h>
static unsigned int my_nf_hookfn(void *priv,
struct sk_buff *skb,
const struct nf_hook_state *state)
{
/* process packet */
//...
return NF_ACCEPT;
}
static struct nf_hook_ops my_nfho = {
.hook = my_nf_hookfn,
.hooknum = NF_INET_LOCAL_OUT,
.pf = PF_INET,
.priority = NF_IP_PRI_FIRST
};
int __init my_hook_init(void)
{
return nf_register_net_hook(&init_net, &my_nfho);
}
void __exit my_hook_exit(void)
{
nf_unregister_net_hook(&init_net, &my_nfho);
}
module_init(my_hook_init);
module_exit(my_hook_exit);
netcat¶
When developing applications that include networking code, one of the most used tools is netcat. Also nicknamed "Swiss-army knife for TCP / IP". It allows:
- Initiating TCP connections;
- Waiting for a TCP connection;
- Sending and receiving UDP packets;
- Displaying traffic in hexdump format;
- Run a program after establishing a connection (eg, a shell);
- Set special options in sent packages.
Initiating TCP connections:
nc hostname port
Listening to a TCP port:
nc -l -p port
Sending and receiving UDP packets is done adding the -u command line option.
Note
The command is nc; often netcat is an alias for this command. There are other implementations of the netcat command, some of which have slightly different parameters than the classic implementation. Run man nc or nc -h to check how to use it.
For more information on netcat, check the following tutorial.
Further reading¶
- Understanding Linux Network Internals
- Linux IP networking
- The TUX Web Server
- Beej's Guide to Network Programming Using Internet Sockets
- Kernel Korner - Network Programming in the Kernel
- Hacking the Linux Kernel Network Stack
- The netfilter.org project
- A Deep Dive Into Iptables and Netfilter Architecture
- Linux Foundation Networking Page
Exercises¶
Important
To solve exercises, you need to perform these steps:
- prepare skeletons from templates
- build modules
- copy modules to the VM
- start the VM and test the module in the VM.
The current lab name is networking. See the exercises for the task name.
The skeleton code is generated from full source examples located in
tools/labs/templates. To solve the tasks, start by generating
the skeleton code for a complete lab:
tools/labs $ make clean
tools/labs $ LABS=<lab name> make skels
You can also generate the skeleton for a single task, using
tools/labs $ LABS=<lab name>/<task name> make skels
Once the skeleton drivers are generated, build the source:
tools/labs $ make build
Then, copy the modules and start the VM:
tools/labs $ make copy
tools/labs $ make boot
The modules are placed in /home/root/skels/networking/<task_name>.
Alternatively, we can copy files via scp, in order to avoid restarting the VM. For additional details about connecting to the VM via the network, please check Connecting to the Virtual Machine.
Review the Exercises section for more detailed information.
Warning
Before starting the exercises or generating the skeletons, please run git pull inside the Linux repo, to make sure you have the latest version of the exercises.
If you have local changes, the pull command will fail. Check for local changes using git status.
If you want to keep them, run git stash before pull and git stash pop after.
To discard the changes, run git reset --hard master.
If you already generated the skeleton before git pull you will need to generate it again.
Important
You need to make sure that the netfilter support is active in kernel. It
is enabled via CONFIG_NETFILTER. To activate it, run make menuconfig in
the linux directory and check the Network packet filtering framework
(Netfilter) option in Networking support -> Networking options. If it
was not enabled, enable it (as builtin, not external module - it must be
marked with *).
1. Displaying packets in kernel space¶
Write a kernel module that displays the source address and port for TCP packets
that initiate an outbound connection. Start from the code in
1-2-netfilter and fill in the areas marked with TODO 1, taking into
account the comments below.
You will need to register a netfilter hook of type NF_INET_LOCAL_OUT as explained
in the netfilter section.
The struct sk_buff structure lets you access the packet headers using
specific functions. The ip_hdr() function returns the IP header as a
pointer to a struct iphdr structure. The tcp_hdr() function
returns the TCP header as a pointer to a struct tcphdr structure.
The diagram explains how to make a TCP connection. The connection initiation
packet has the SYN flag set in the TCP header and the ACK flag cleared.
Note
To display the source IP address, use the %pI4 format of the printk
function. Details can be found in the kernel documentation (IPv4
addresses section). The following is an example code snippet that uses
%pI4:
printk("IP address is %pI4\n", &iph->saddr);
When using the %pI4 format, the argument to printk is a pointer. Hence the
construction &iph->saddr (with operator & - ampersand) instead of
iph->saddr.
The source TCP port is, in the TCP header, in the network byte-order format.
Read through the Conversions section. Use ntohs() to convert.
For testing, use the 1-2-netfilter/user/test-1.sh file. The test creates
a connection to the localhost, a connection that will be intercepted and
displayed by the kernel module. The script is copied on the virtual machine by
the make copy command only if it is marked as executable. The script
uses the statically compiled netcat tool stored in
skels/networking/netcat; this program must have execution
permissions.
After running the checker the output should be similar to the one bellow:
# ./test-1.sh
[ 229.783512] TCP connection initiated from 127.0.0.1:44716
Should show up in filter.
Check dmesg output.
2. Filtering by destination address¶
Extend the module from exercise 1 so that you can specify a destination address
by means of a MY_IOCTL_FILTER_ADDRESS ioctl call. You'll only show packages
containing the specified destination address. To solve this task, fill in the
areas marked with TODO 2 and follow the specifications below.
To implement the ioctl routine, you must fill out the my_ioctl function.
Review the section in ioctl. The address sent from user space is in
network byte-order, so there will be NO need for conversion.
Note
The IP address sent via ioctl is sent by address, not by value. The
address must be stored in the ioctl_set_addr variable. For copying use
copy_from_user().
To compare the addresses, fill out the test_daddr function. Addresses in
network byte-order will be used without having to convert addresses (if they
are equal from left to right they will be equal if reversed too).
The test_daddr function must be called from the netfilter hook to display
the connection initialization packets for which the destination address is the
one sent through the ioctl routine. The connection initiation packet has the
SYN flag set in the TCP header and the ACK flag cleared. You have to
check two things:
- the TCP flags;
- the destination address of the packet (using
test_addr).
For testing, use the 1-2-netfilter/user/test-2.sh script. This script
needs to compile the 1-2-netfilter/user/test.c file in the test
executable. Compilation is done automatically on the physical system when
running the make build command. The test script is copied to the
virtual machine only if it is marked as executable. The script uses the
statically compiled netcat tool in skels/networking/netcat;
this executable must have execution permissions.
After running the checker the output should be similar to the one bellow:
# ./test-2.sh
[ 797.673535] TCP connection initiated from 127.0.0.1:44721
Should show up in filter.
Should NOT show up in filter.
Check dmesg output.
The test ask for packet filtering first for the 127.0.0.1 IP address and
then for the 127.0.0.2 IP address. The first connection initiation packet
(to 127.0.0.1) is intercepted and displayed by the filter, while the second
(to 127.0.0.2) is not intercepted.
3. Listening on a TCP socket¶
Write a kernel module that creates a TCP socket that listens to connections on
port 60000 on the loopback interface (in init_module). Start from the
code in 3-4-tcp-sock fill in the areas marked with TODO 1 taking
into account the observations below.
Read the Operations on the socket structure and The struct proto_ops structure sections.
The sock socket is a server socket and must be put in the listening
state. That is, the bind and listen operations must be applied to the
socket. For the bind and listen equivalent, in kernel space you will
need to call sock->ops->...; examples of such functions you can call are
sock->ops->bind, sock->ops->listen etc.
Note
For example, call sock->ops->bind, or sock->ops->listen functions, see
how they are called in the sys_bind() and sys_listen() system
call handlers.
Look for the system call handlers in the net/socket.c file in the Linux
kernel source code tree.
Note
For the second argument of the listen (backlog) call, use the
LISTEN_BACKLOG.
Remember to release the socket in the module's exit function and in the area
marked with error labels; use sock_release().
For testing, run the 3-4-tcp_sock/test-3.sh script. The script is copied on the virtual machine by make copy only if it is marked as executable.
After running the test, a TCP socket will be displayed by listening to
connections on port 60000.
4. Accepting connections in kernel space¶
Expand the module from the previous exercise to allow an external connection (no
need to send any message, only accept new connections). Fill in the areas marked
with TODO 2.
Read the Operations on the socket structure and The struct proto_ops structure sections.
For the kernel space accept equivalent, see the system call handler for
sys_accept4(). Follow the lnet_sock_accept
implementation, and how the sock->ops->accept call is used. Use 0 as
the value for the second to last argument (flags), and true for the
last argument (kern).
Note
Look for the system call handlers in the net/socket.c file in the Linux
kernel source code tree.
Note
The new socket (new_sock) must be created with the
sock_create_lite() function and then its operations must be configured
using
newsock->ops = sock->ops;
Print the address and port of the destination socket. To find the peer name of a
socket (its address), refer to the sys_getpeername() system call handler.
Note
The first argument for the sock->ops->getname function will be the
connection socket, ie new_sock, the one initialized with by the accept
call.
The last argument of the sock->ops->getname function will be 1,
meaning that we want to know about the endpoint or the peer (remote end or
peer).
Display the peer address (indicated by the raddr variable) using the
print_sock_address macro defined in the file.
Release the newly created socket (after accepting the connection) in the module
exit function and after the error label. After adding the accept code to the
module initialization function, the insmod operation will lock until
a connection is established. You can unlock using netcat on that
port. Consequently, the test script from the previous exercise will not work.
For testing, run the 3-4-tcp_sock/test-4.sh script. The script is copied on
the virtual machine by make copy only if it is marked as executable.
Nothing special will be displayed (in the kernel buffer). The success of the
test will be defined by the connection establishment. Then use Ctrl+c to
stop the test script, and then you can remove the kernel module.
5. UDP socket sender¶
Write a kernel module that creates a UDP socket and sends the message from the
MY_TEST_MESSAGE macro on the socket to the loopback address on port
60001.
Start from the code in 5-udp-sock.
Read the Operations on the socket structure and The struct proto_ops structure sections.
To see how to send messages in the kernel space, see the sys_send()
system call handler or Sending/receiving messages.
Hint
The msg_name field of the struct msghdr structure must be
initialized to the destination address (pointer to struct sockaddr)
and the msg_namelen field to the address size.
Initialize the msg_flags field of the struct msghdr structure
to 0.
Initialize the msg_control and msg_controllen fields of the
struct msghdr structure to NULL and 0 respectively.
For sending the message use kernel_sendmsg().
The message transmission parameters are retrieved from the kernel space. Cast
the struct iovec structure pointer to a struct kvec pointer
in the kernel_sendmsg() call.
Hint
The last two parameters of kernel_sendmsg() are 1 (number of I/O
vectors) and len (message size).
For testing, use the test-5.sh file. The script is copied on the virtual
machine by the make copy command only if it is marked as executable.
The script uses the statically compiled netcat tool stored in
skels/networking/netcat; this executable must have execution
permissions.
For a correct implementation, running the test-5.sh script will cause
the kernelsocket message to be displayed like in the output below:
/root # ./test-5.sh
+ pid=1059
+ sleep 1
+ nc -l -u -p 60001
+ insmod udp_sock.ko
kernelsocket
+ rmmod udp_sock
+ kill 1059